LLM의 환각 현상을 해결하는 RAG 및 Groundedness Check
2024/03/08 | 작성자: 최유정 (테크니컬 라이터)
RAG란 무엇이며 왜 필요한가요?
비즈니스에서 LLM을 서비스로 구현할 때 가장 우려되는 점은 무엇인가요? 많은 사람들이 가장 우려하는 것은 환각 현상으로 인한 LLM의 불안정성입니다. LLM이 제공하는 응답이 랜덤하게 느껴진다면 경우가 많은데 우리가 어떻게 LLM이 적절한 결과를 제공한다고 신뢰할 수 있을까요?
해결책은 Retrieval Augmented Generation의 줄임말인 RAG에 있습니다. 이 접근 방식은 관련 문서에서 레퍼런스를 제공함으로써 응답에 근거를 더해주어 LLM의 내재적 문제를 완화합니다. 유저의 쿼리가 원하는 정확한 정보를 언어 모델에게 함께 제공하여 LLM이 근거가 없거나 관련 없는 답변을 생성하는 경향을 크게 줄입니다. 아래에서 RAG 시스템을 자세히 살펴보겠습니다.

RAG 및 Groundedness Check 파이프라인
환각 문제 정보
OTT 서비스용 LLM을 개발 중이라고 가정해 보겠습니다. 사용자가 "친구들과 함께 볼 수 있는 좋은 영화를 추천해 주세요. 저희는 4명이고 80년대 후반의 공포 영화를 좋아해요."라는 질문을 던질 수 있습니다.
영화 관련 데이터에 대한 훈련이 되어 있지 않은 경우, LLM의 환각 문제가 발생할 가능성이 높습니다. 생성된 답변이 사실과 다를 수 있지만, 검색하기 전에는 이를 인지하지 못할 수 있습니다. 예를 들어, LLM은 그런 영화가 존재하지 않는데도 "그럼요! 80년대 유명 여배우가 출연한 '숲속의 비명'은 어때요?"라고 말할 수 있습니다. 이 문제는 다음 단어 예측에 의존하여 가장 그럴듯한 단어를 선택하는 언어 모델의 핵심 기능에 뿌리를 두고 있습니다. 언어 모델은 출력 결과가 사실인지 아닌지는 신경 쓰지 않고 이 단어 다음에 나올 가능성이 가장 높은 단어만 신경 씁니다.
RAG 시스템에 대한 기본적인 이해
RAG 시스템은 어떻게 LLM이 근거에 입각한 답변을 생성하는 데 필요한 토대를 갖추고 출처를 완비할 수 있도록 지원하나요?
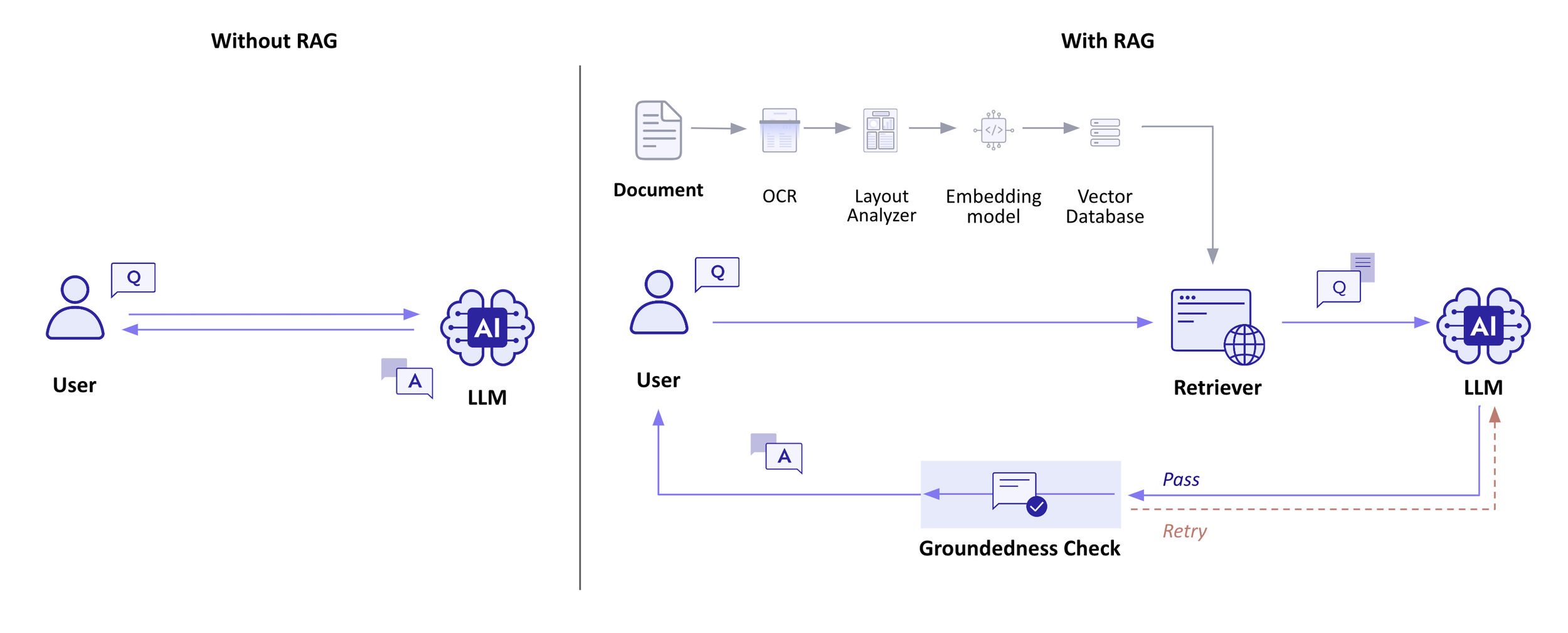
RAG 포함 및 미포함 그림
RAG의 첫 번째 단계는 자체 데이터를 임베딩 모델에 통합하는 것입니다. 텍스트 데이터를 벡터 형식으로 변환하여 벡터 데이터베이스를 구축합니다. 벡터화된 정보가 풍부한 이 데이터베이스는 Retriever 부분에서 사용자의 쿼리와 관련된 정보를 찾을 수 있는 근거를 마련합니다.
Groundedness Check 살펴보기
Groundednesss는 마지막 단계로서 시스템의 신뢰성을 크게 강화합니다. 사용자에게 답변이 전달되기 전에 유효성을 검사함으로써 제공된 정보의 정확성을 보장합니다. 이 중요한 단계는 환각의 가능성을 거의 제로에 가깝게 낮춥니다.
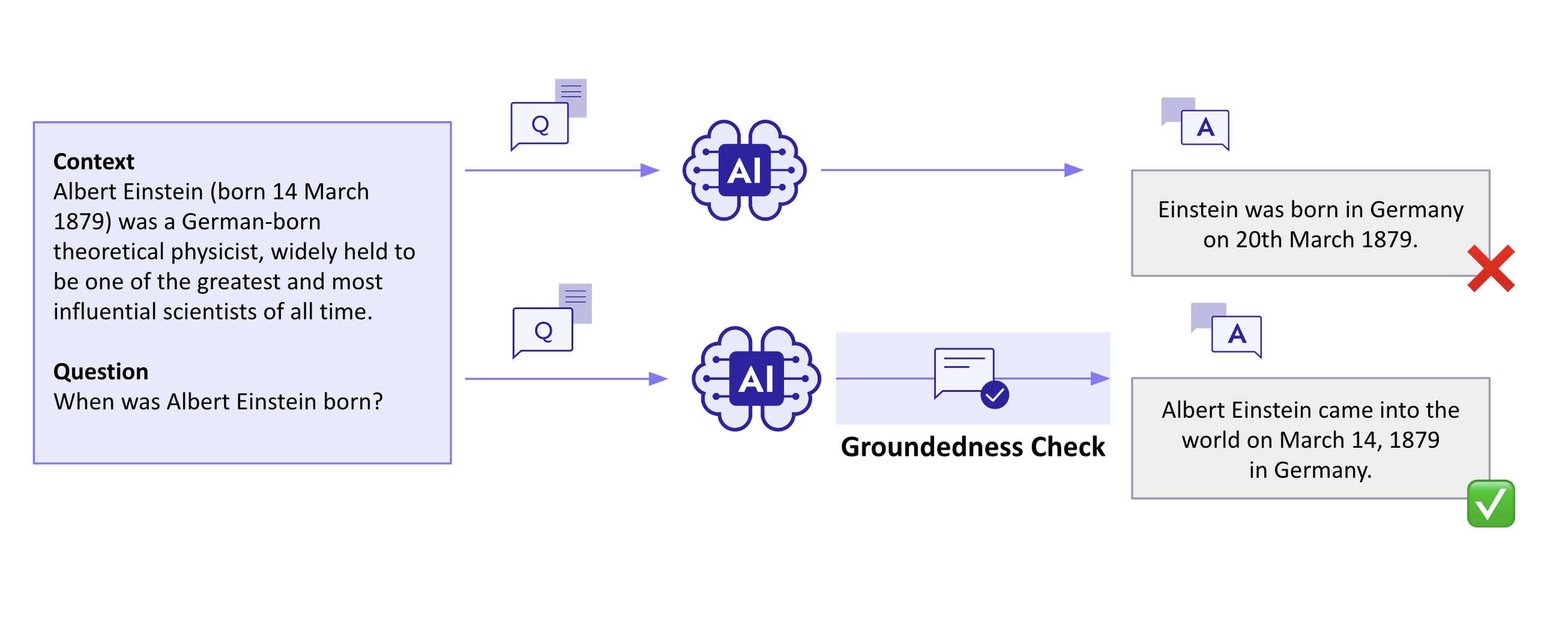
With and without Groundedness Check
RAG는 LLM의 환각 문제를 상당 부분 해결하지만, Groundedness Check는 응답의 정확성을 확인하는 안전장치 역할을 합니다. 제공된 예시를 살펴보면 첫 번째 사례에서와 같이 RAG만으로는 사용자에게 부정확한 초기 응답이 표시되는 것을 방지하지 못할 수 있습니다. 그러나 Groundedness Check를 사용하면 응답을 LLM으로 리디렉션하여 수정할 수 있는 기회를 제공할 수 있습니다.
이 근거 확인 프로세스는 출력이 참조 문서의 내용과 일치하는지 꼼꼼하게 확인합니다. 답변이 검색된 데이터와 일치하는지 확인함으로써 모델의 출력이 제공된 컨텍스트에 확고하게 고정되어 있는지 확인하여 답변이 주어진 정보와 다른 결과를 제공하는 것을 방지합니다.
사례 연구
이 섹션에서는 RAG가 실제 서비스에서 LLM의 배포를 어떻게 도울 수 있었는지에 대해 설명합니다.
데이터 양이 너무 많나요? 가능합니다.
업스테이지가 LLM과 함께 한국언론진흥재단과 함께 주목할 만한 성과를 거뒀습니다. 한국언론연구원의 고객은 방대한 뉴스 빅데이터 시스템을 개선하고자 했지만, 방대한 데이터 집합이라는 문제에 직면해 있었습니다. 약 80,000,000건에 달하는 30년 이상 축적된 뉴스 데이터의 정보에 액세스해야 했습니다.
RAG 를 사용하기 위해서 방대한 데이터베이스를 적절한 시간 내에 검색해야 했습니다. 이를 위해 dense search 와 sparse search 방법을 병합하여 속도와 정확성의 균형을 맞추는 하이브리드 검색 기법을 구현했습니다. 이 사례를 통해 업스테이지는 8천만 건의 방대한 기사 속에서 질문에 관련된 문서를 신속하게 검색하여 서비스를 제공하는 경험을 쌓았습니다.
RAG와 Fine-tuning이 한 번에 필요하신가요? 가능합니다.
두 번째 사례는 엔터테인먼트 회사와의 협업을 통해 뚜렷한 페르소나를 가진 LLM 대화형 에이전트를 개발하는 것이었습니다. 사용자와 관계를 유지할 수 있는 에이전트를 만드는 것이 과제였는데, 이를 위해서는 자신에 대한 사실을 기억하고 사용자와의 이전 대화를 기억할 수 있는 기능이 필요했습니다. 또한 언어 모델에는 사람과 유사한 대화형 에이전트의 일반적인 문제인 적대적 공격과 탈옥 시도에 대응할 수 있는 강력한 안전장치가 필요했습니다.
페르소나를 구축하고, 사용자 관계를 유지하며, LLM에 대한 안전장치를 구현하기 위해 RAG와 미세 조정을 결합하여 원하는 서비스 수준을 달성했습니다. 사용자와의 대화 맥락을 유지하는 단기 메모리와 상담원의 페르소나를 보존하는 장기 메모리로 메모리를 분리하는 시스템을 개발했습니다. RAG와 미세 조정을 통합하는 이 혁신적인 접근 방식을 통해 복잡하지만 인간과 유사한 대화 기능을 가진 LLM이 탄생할 수 있었습니다.
데이터는 어떻게 준비하나요? 레이아웃 분석
참조 텍스트를 검색하기 위한 신뢰할 수 있는 데이터 세트를 만드는 것은 특히 답변이 데이터에 정확하게 근거를 두고 있는지 확인하는 데 중요합니다. "가비지 인, 가비지 아웃"이라는 딥러닝의 모토는 언어 모델에 제공되는 데이터 품질의 중요성을 강조합니다. LLM을 위한 문서를 준비하려면 레이아웃 분석이 매우 유용한 도구입니다.
다음은 Upstage에 대한 가상의 문서로 살펴보는 예시입니다.

이와 같은 형태의 PDF 형식 문서가 있다면 이는 비정형 문서입니다. 그렇다면 어떻게 데이터를 벡터 데이터베이스에 맞게 구조화할 수 있을까요? OCR(광학 문자 인식)로 충분할까요?

OCR만으로는 충분하지 않습니다! LLM이 데이터를 정확하게 해석하려면 문서의 레이아웃을 인식하는 것이 필수적입니다. 단순히 OCR만 수행하면 표나 서식과 같이 문서 레이아웃을 통해 전달되는 암시적 정보를 놓치게 됩니다. 따라서 레이아웃 분석을 포함하는 총체적인 접근 방식은 LLM 통합을 위해 데이터를 철저하게 준비하는 데 매우 중요합니다.
요약
결국 모든 것은 이것으로 귀결됩니다. RAG는 데이터로 답변의 근거를 마련하고, 근거 확인은 답변을 다시 확인하며, 레이아웃 분석은 이 데이터를 준비합니다. 이러한 도구와 구성요소를 통해 업스테이지의 LLM Solar를 비즈니스에 바로 활용할 수 있습니다.